


Cohere
1M token/$1.00
Initial Release: 2021-11-15
help enterprises build powerful, secure applications
the industry’s highest performing embedding model
Search performance improvement
price
Starting from :$1.0/1M TOKENS
Description
what is Cohere?
Cohere’s world-class large language models (LLMs) help enterprises build powerful, secure applications that search, understand meaning and converse in text.
Cohere allows developers and enterprises to build LLM-powered applications. it do that by creating world-class models, and the supporting platform to deploy them securely and privately.
Command is Cohere’s text generation LLM which powers conversational agents, summarization, copywriting, and similar use cases. It works through the following endpoints:
co.chatis used to build conversational agents, with or without RAGco.generateis used for text generation that is non-conversational in natureco.summarizeis used for long-text summarization
Rerank is the fastest way to inject the intelligence of a language model into an existing search system. It can be accessed via the co.rerank endpoint.
Embed improves the accuracy of search, classification, clustering, and retrieval-augmented generation (RAG) results. It powers the Embed, Classify, and Cluster endpoints.
These LLMs Make it Easy to Build Conversational Agents (and Other LLM-powered Apps)
Try Coral to see what an LLM-powered conversational agent can look like. It is able to converse, summarize text, and write emails and articles.
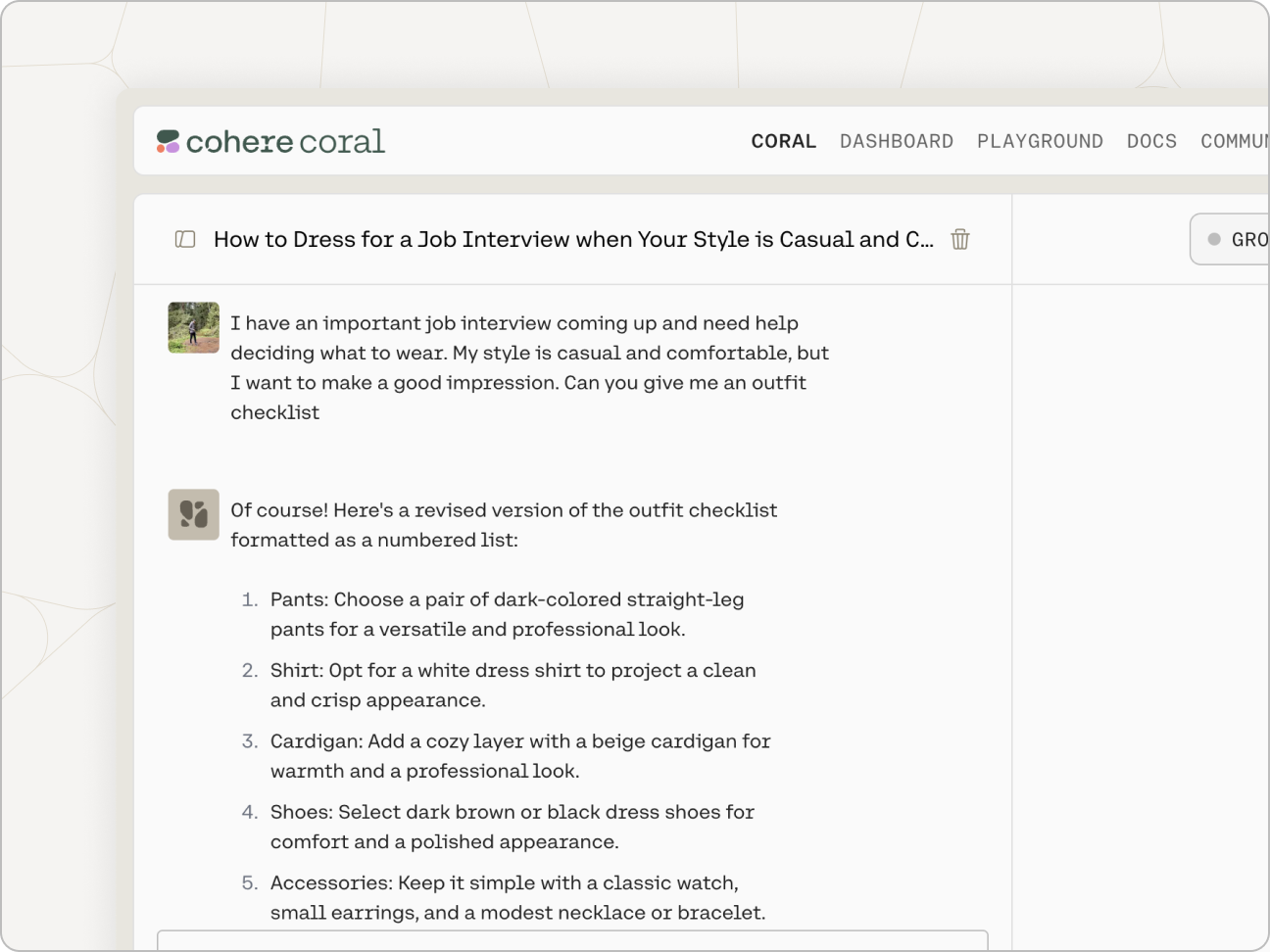
Their goal, however, is to enable you to build your own LLM-powered applications. The Chat endpoint, for example, can be used to build a conversational agent powered by the Command model.
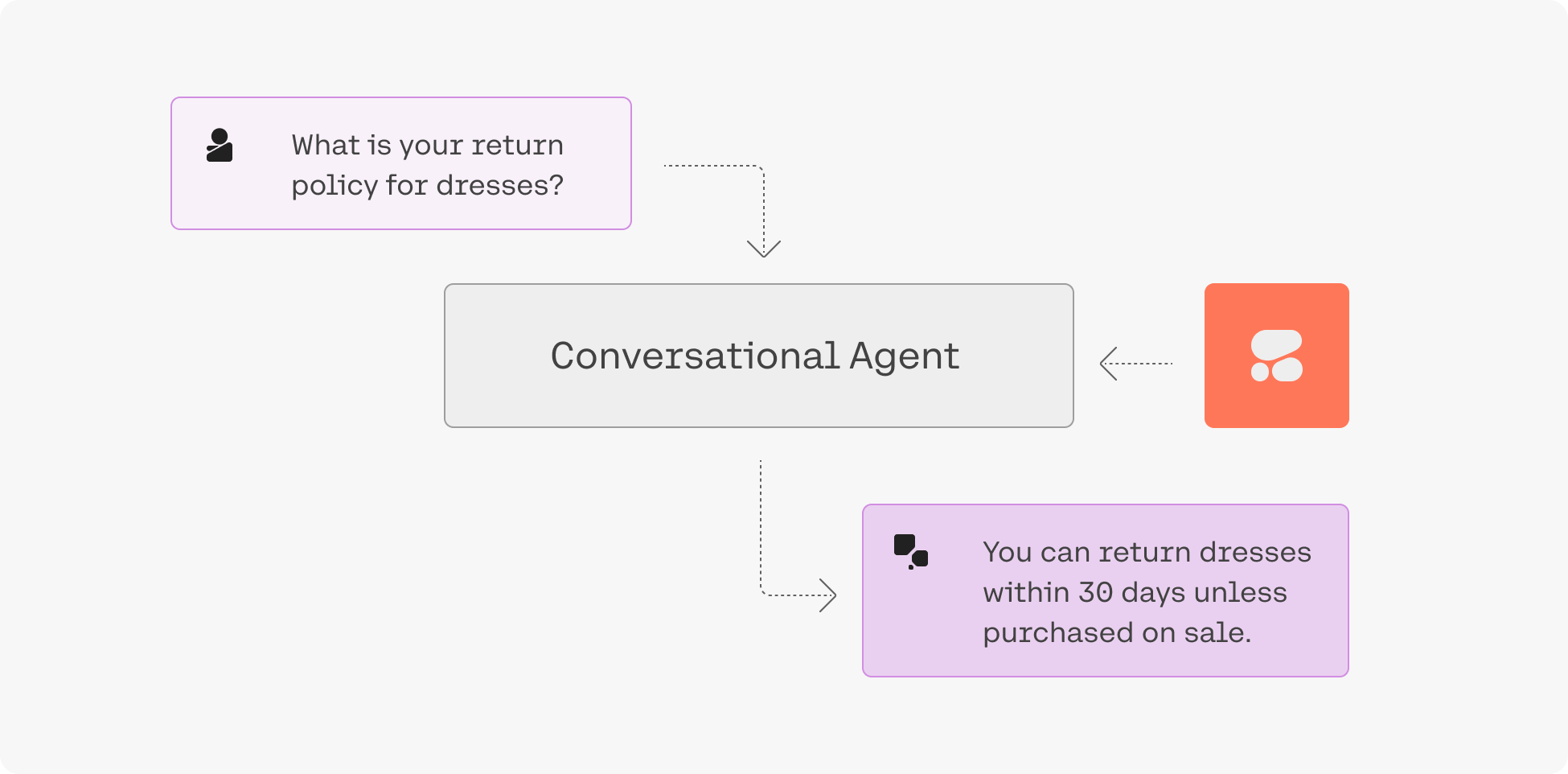
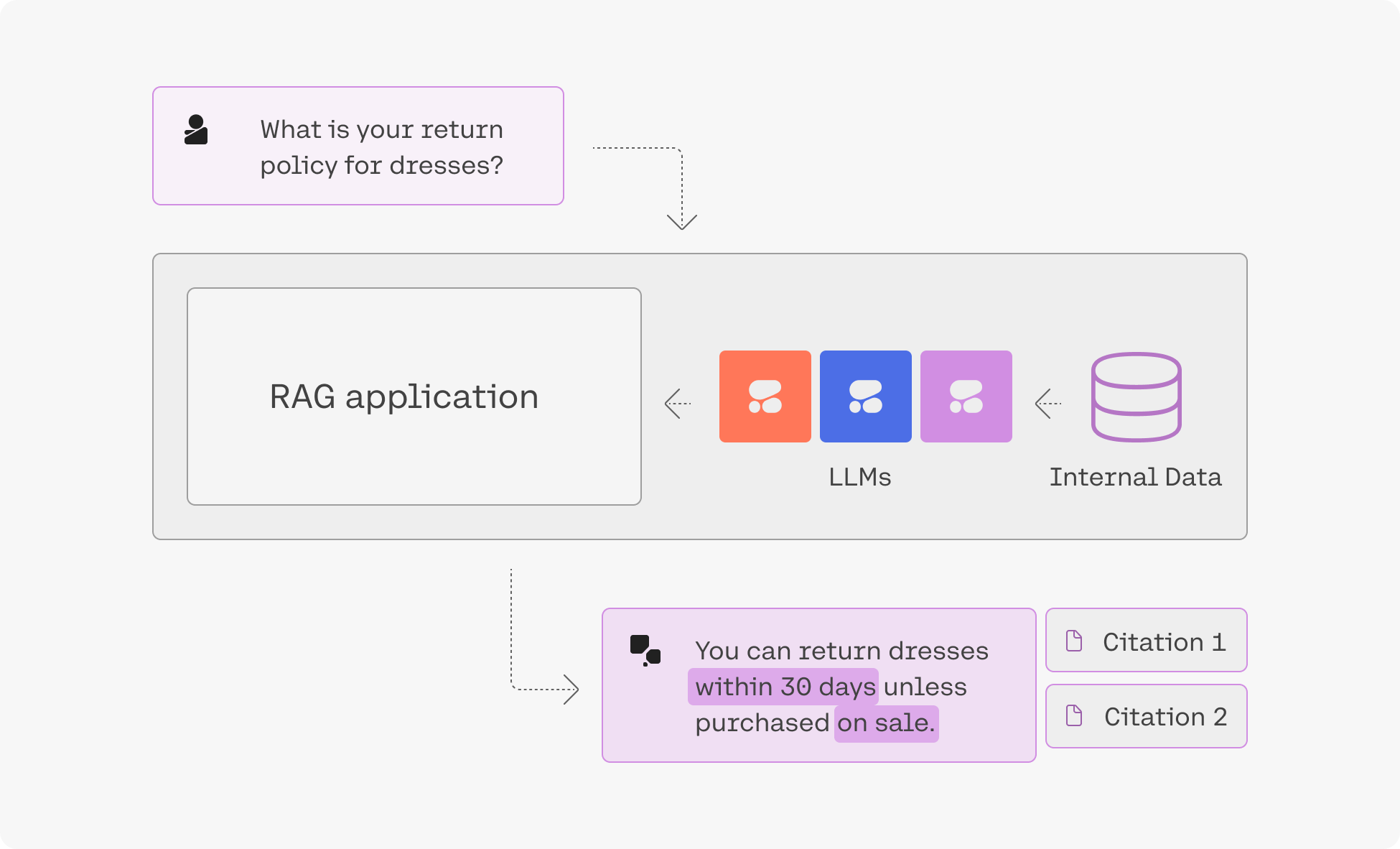
Retrieval-Augmented Generation (RAG)
“Grounding” refers to the practice of allowing an LLM to access external data sources – like the internet or a company’s internal technical documentation – which leads to better, more factual generations. Coral is being used with grounding enabled in the screenshot below, and you can see how accurate and information-dense its reply is.
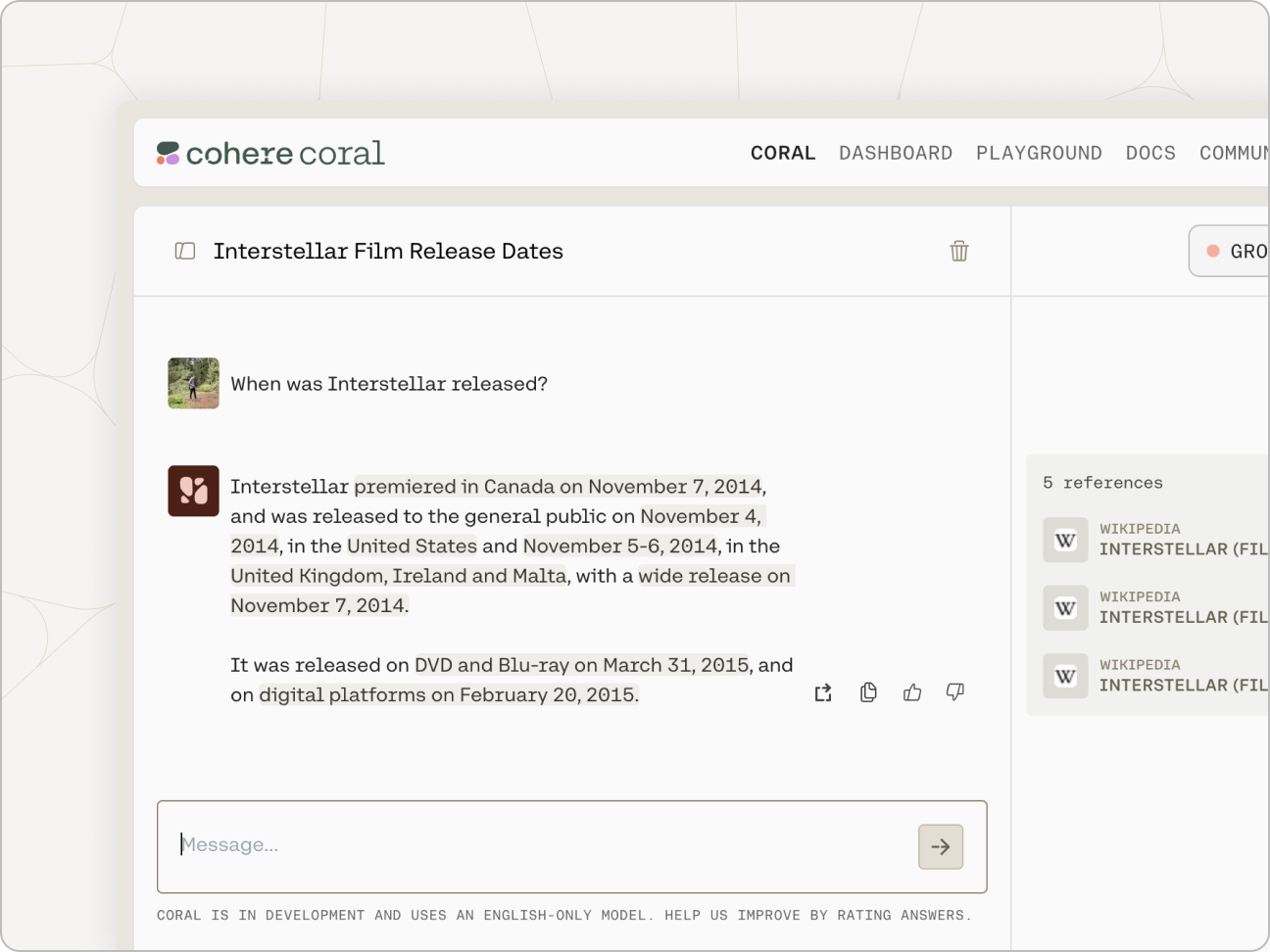
What’s more, Coral’s advanced RAG capabilities allow you to see what underlying query the model generates when completing its tasks, and its output includes citations pointing you to where it found the information it uses. Both the query and the citations can be leveraged alongside Cohere’s Embed and Rerank models to build a remarkably powerful RAG system, such as the one found in this guide.
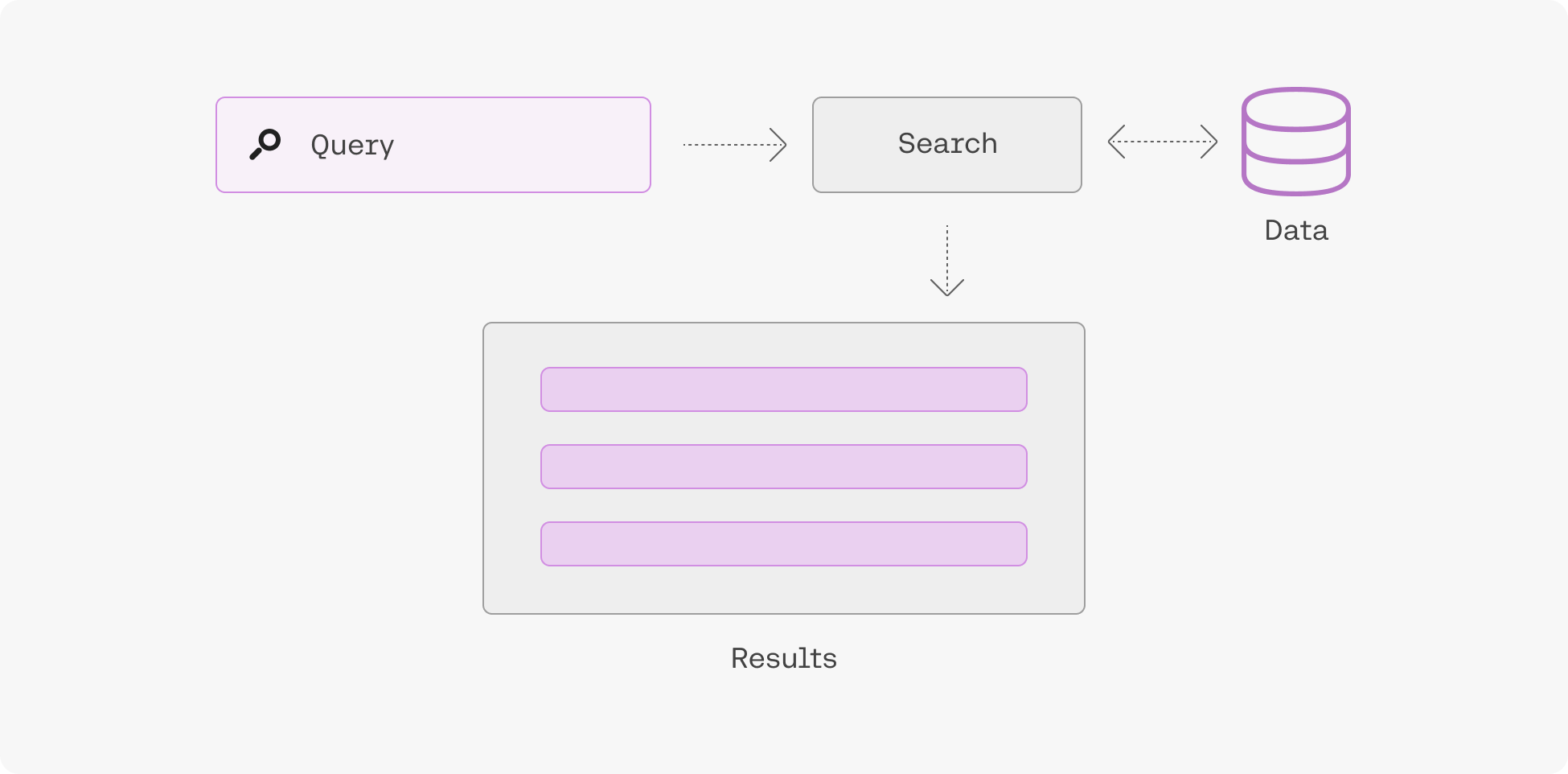
Use Language Models to Build Better Search and RAG Systems
Embeddings enable you to search based on what a phrase means rather than simply what keywords it contains, leading to search systems that incorporate context and user intent better than anything that has come before.
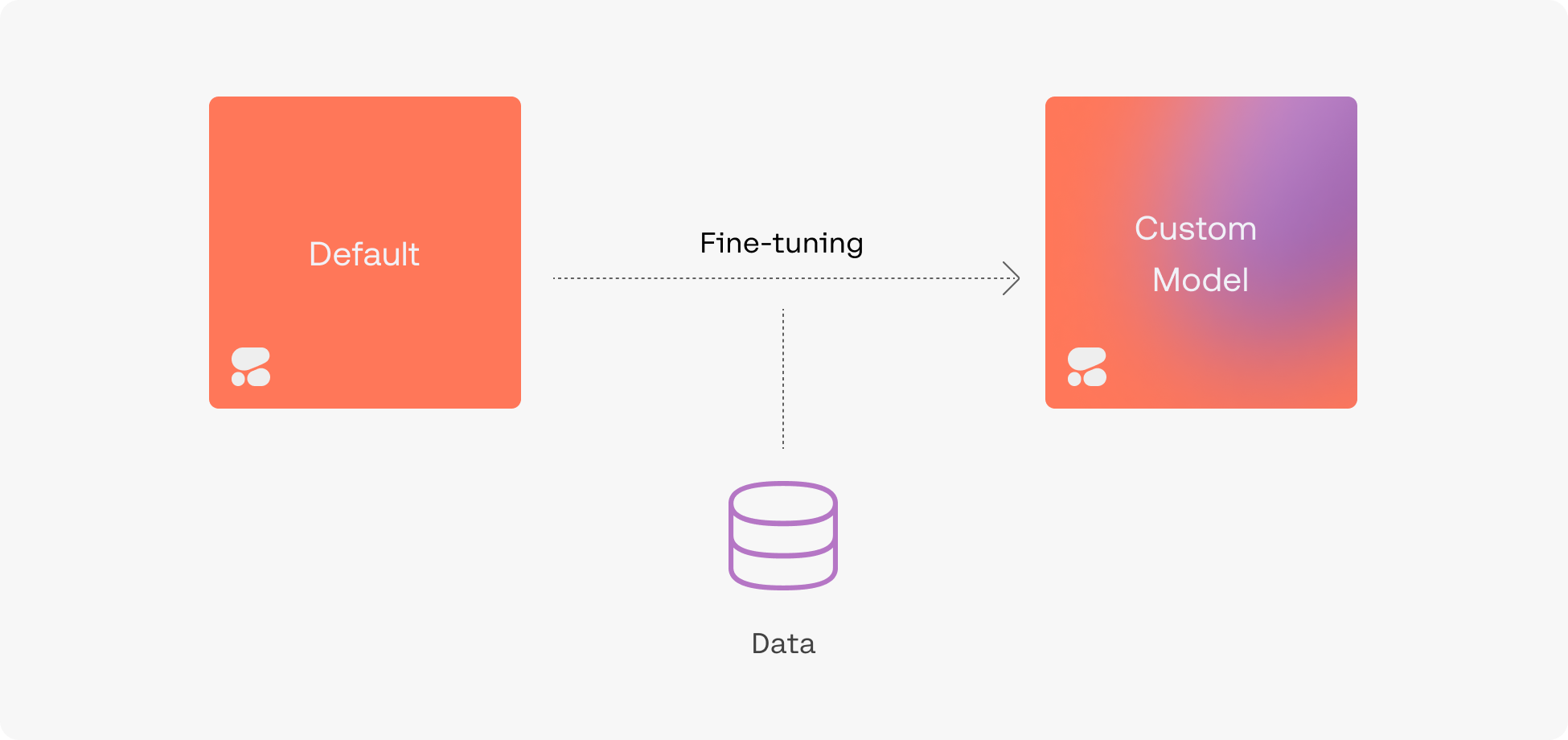
Create Fine-Tuned Models with Ease
To create a fine-tuned model, simply upload a dataset and hold on while we train a custom model and then deploy it for you. Fine-tuning can be done with generative models, chat models, rerank models, and multi-label classification models.
Private and Secure Deployment Options
You can connect to the Cohere API directly, or access the models privately on the four major cloud providers.

price:







Reviews
There are no reviews yet.